The Check Models view lets you compare the accuracy of models generated from your feature selections. Depending on your target, Distil builds models of the following types:
- Classification models when your target is categorical
- Regression models when your target is continuous
- Forecasting models when you target is a timeseries
Because Event_Type is a categorical feature, Distil generates classification models for this example. Once you have inspected them, you can either:
- Return to the previous step to refine your model definition, or
- Save the one you think is most accurate
Review model results
In the Check Models view, you can inspect the models generated by Distil to:
- Determine which one is most accurate
- Understand how specific features and values influence the results.
The Check Models view is made up of the following components:
Model Results pane
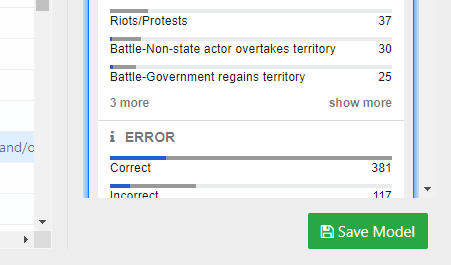
The Model Results pane on the right lists each model that Distil generated for your problem. Distil ranks the models in descending order of estimated accuracy.
To inspect the predictions generated by the model:
- Scroll through the models at the bottom of the pane.
- Compare the distribution of predictions in each model against the distribution of the actual values from the dataset. Which model looks most similar to the actual target feature?
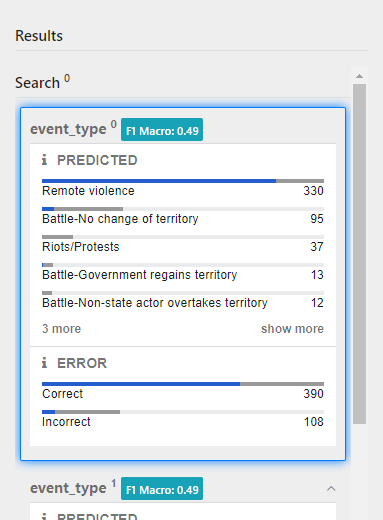
- Select a category in the results to split the Prediction tables based on the corresponding values.
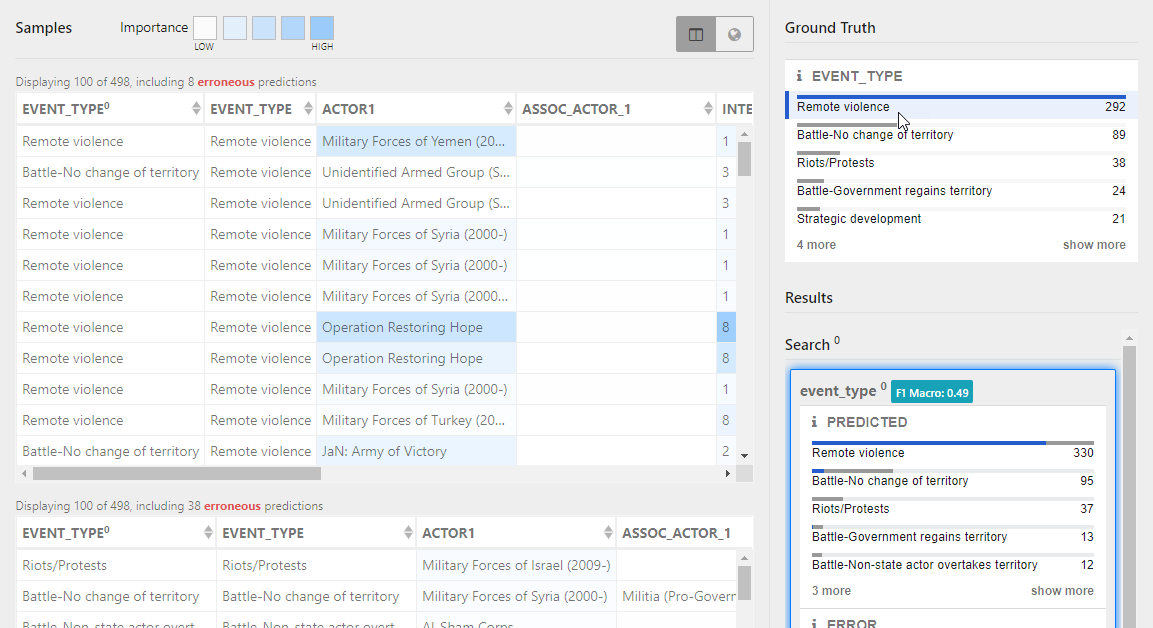
The top table lists records that match your selection, while the bottom table lists all other records.
- Click a different model to load its results in the Prediction Tables.
-
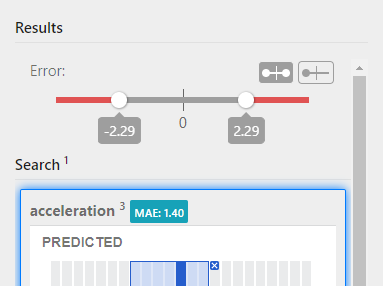
Review the distribution of error in the predicted results. Is the error relatively consistent across all the predictions?
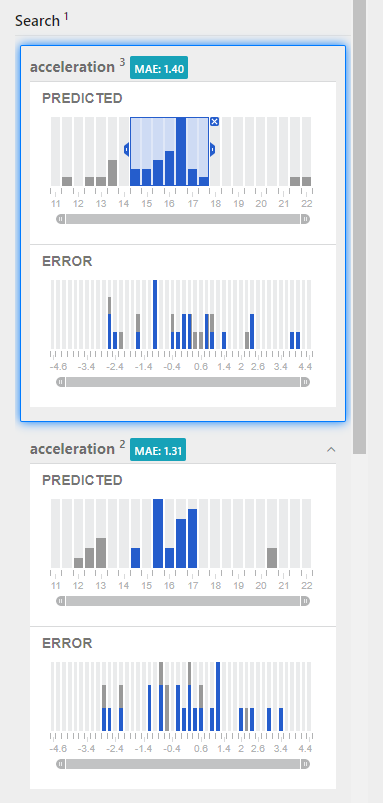
Error charts are centered on 0. Positive error values indicate that the prediction was higher than the actual value, while negative error values indicate the opposite.
- Drag the left or right error sliders to adjust the acceptable error in the predictions. By default, Distil sets the acceptable error to the 25th percentile. How does changing this value affect the number of correct/incorrect predictions?
To view a different model:
- Compare the ranges of predicted values and error in the model summaries.
- Click the model you want to review to refresh the Prediction Tables.
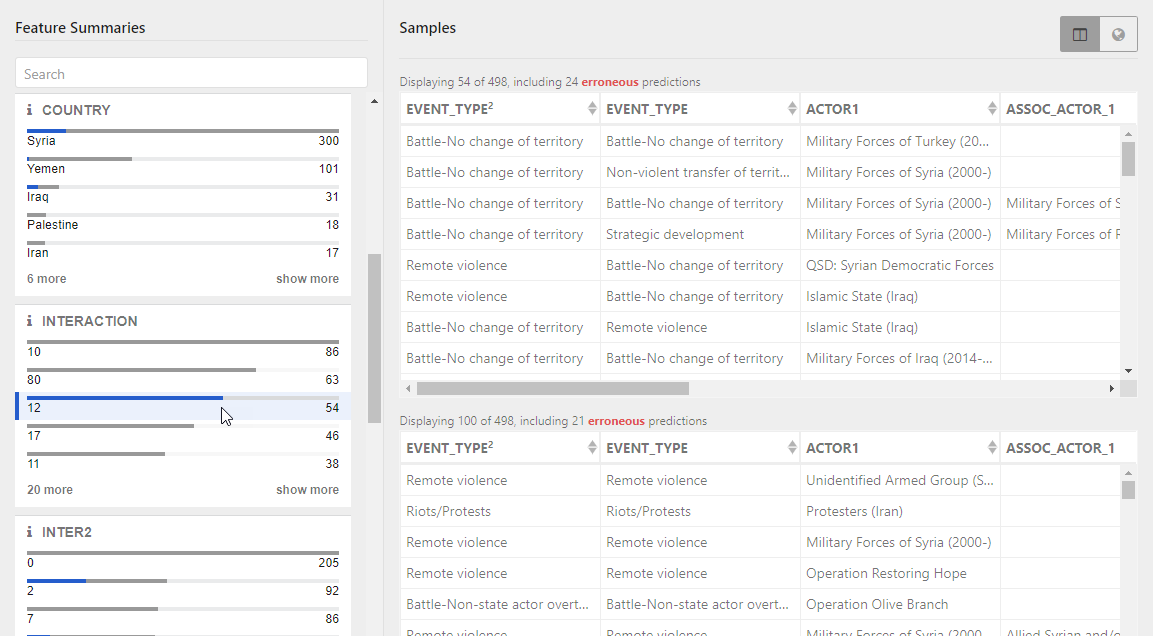
Prediction tables
The Prediction tables list records that the model predicted. When you first access the Check Models page, a single Prediction table lists all the records. As you interact with feature summaries or model predictions to filter the view, the Prediction table splits into:
- Matching samples that contain the selected values.
- Other samples that do not.
You can compare the results in the two tables to understand how certain values affect the correctness of the predictions.
To split the predictions tables:
- Select a category or a range of values in the target feature, feature summaries, or model predictions. What values do correct and incorrect predictions tend to have?
Feature summaries
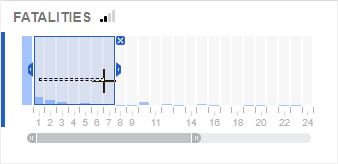
The Feature summaries show the range of values in the features used to model the predictions. The distribution of values can help you understand how they influence correct/predictions. You can filter the Prediction tables on specific values to understand how results would change if you omitted them from the model.
To understand how the models would change if you omitted records with specific values:
- For continuous features, drag a selection on the timeline to focus on records that contain values beyond the selection. Does this improve the predictions?
- For categorical features, click to select individual values. Does this improve the predictions?
Refine a model
To refine the models that Distil produced, click New Model: Select Target or Create Models to go back to a previous step.
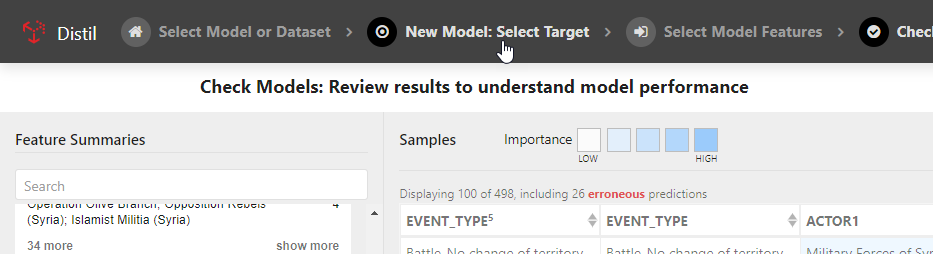
When refining the model, you can change the target feature, add or remove features used to model the predictions, or adjust the values included for specific features.
Finish a problem
When you are satisfied with the results of a model, click Save Model to make it available from the start page and enable to ability to apply it to make predictions on new datasets.